Dato Distributed Introduction
In this chapter, we demonstrate how to use Dato Distributed, a distributed and asynchronous execution framework that makes it easy to take your prototypes to production.
Dato Distributed provides a light-weight framework for creating an environment (for example, in EC2 or Hadoop) for distributed execution and submit jobs to these environments, with loose coupling, and management tools to support asynchronous execution.
In order to work with a Dato Distributed deployment (either on an on-premises cluster, or in the Cloud), you will use a GraphLab Create client. The APIs under graphlab.deploy provide the necessary functionality to create, use, and administer Dato Distributed environments. Moreover, some of the runtime information about distributed job execution can be visualized in GraphLab Canvas.
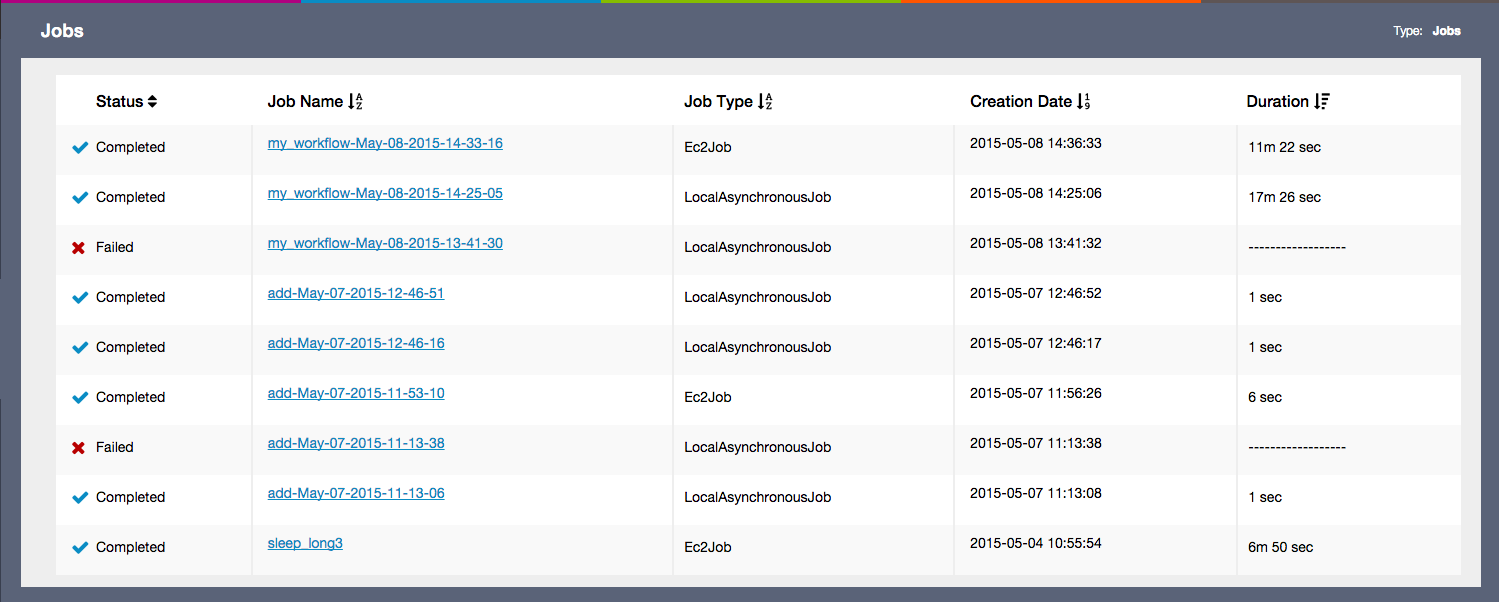
The following chapters provide more details on the following aspects of remote and asynchronous job execution:
Asynchronous Jobs describes how you can execute jobs asynchronously, but still within you local machine. Note that this functionality does not depend on Dato Distributed.
Installing on Hadoop explains how to install Dato Distributed on your local Hadoop environment.
Clusters provides a walk-through of submitting jobs to EC2 as well as Hadoop.
An end-to-end example demonstrates how to implement a recommender and run it as a remote job.
Distributed Machine Learning introduces the concept of executing Dato toolkits in a distributed environment transparently.
Monitoring Jobs outlines how to gain insight into the status and health of previously submitted jobs.
Session Management contains information about how to maintain local references to jobs and environments.
The chapter about Dependencies explains how external packages required by your use case can be included in the job deployment and execution.