Random Forest Classifier
A Random Forest classifier is one of the most effective machine learning models for predictive analytics. Refer to the chapter on random forest regression for background on random forests.
Introductory Example
import graphlab as gl
# Load the data
# The data can be downloaded using
data = gl.SFrame.read_csv('http://s3.amazonaws.com/gl-testdata/xgboost/mushroom.csv')
# Label 'c' is edible
data['label'] = data['label'] == 'c'
# Make a train-test split
train_data, test_data = data.random_split(0.8)
# Create a model.
model = gl.random_forest_classifier.create(train_data, target='label',
max_iterations=2,
max_depth = 3)
# Save predictions to an SArray.
predictions = model.predict(test_data)
# Evaluate the model and save the results into a dictionary
results = model.evaluate(test_data)
We can visualize the models using
model.show(view="Tree", tree_id=0)
model.show(view="Tree", tree_id=1)
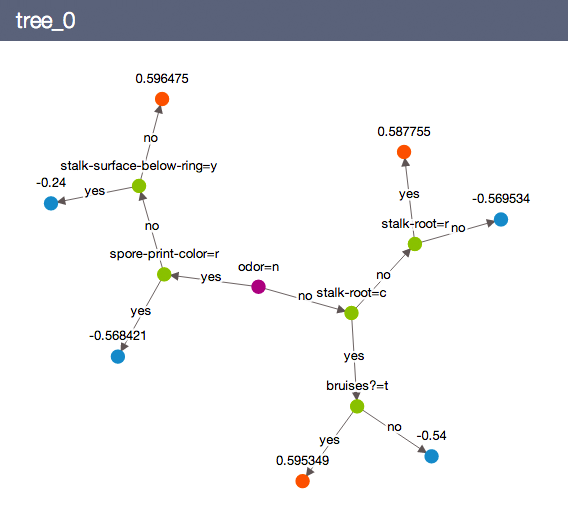
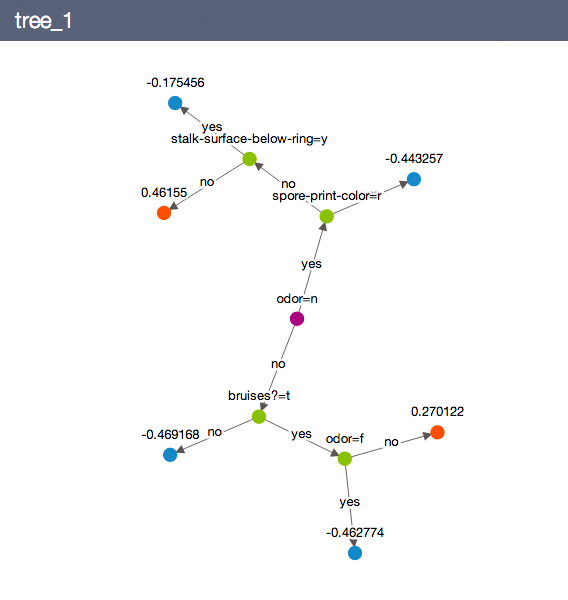
See the chapter on random forest regression for additional tips and tricks of using the random forest classifier model.
Advanced Features
Refer to the earlier chapters for the following features: